
A while back I wrote about bootstrapping a Kubernetes cluster. I’ve been refining the setup so that it requires as little manual kubectl‘ing as possible. I still use ArgoCD to get everything rolling, and there is one bit that kept going red: persistent volumes.

I’m aware many people out there will prefer using managed solutions for any database that requires persistence. Makes sense: stateless, often ephemeral services were supposed to be a central idea in the Kubernetes microservices world. It reminds me a little of functional programming and its insistence on pure functions. Sure it’s a nice thing but eventually you’ll need that IO. Similarly, keeping all your databases outside of the cluster sounds nice, but Prometheus for example pretty much requires being inside.
My setup has Prometheus and Grafana for monitoring. While Grafana doesn’t require persistence to run, it makes life a lot more convenient if it has a place to store settings and dashboards. Prometheus is a time-series database and persistence it pretty much the point of a database.
The problem
I use ArgoCD to monitor the stable Helm chart repository and keep everything up to date. I won’t pretend I understand Argo’s inner workings, but I figure many things can trigger a re-sync of apps. I noticed this because the Prometheus and Grafana deployments kept going red, showing up in Argo as “degraded” or permanently “progressing”. Looking at the Kubernetes Dashboard (Digital Ocean‘s managed Kubernetes comes with it) the problem was pretty obvious.
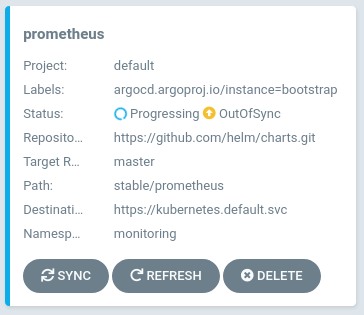
ArgoCD would apply the new deployment, creating a new ReplicaSet. The usual procedure would be for it to wait until the new Pod comes green then scale down the old ReplicaSet. Except the PersistentVolumeClaim uses accessModes ReadWriteOnce, so the new Pod can’t bind the PersistentVolume (getting “multi-attach error”) until the old one let it go. Which won’t happen, of course (it’d mean downtime).
The solution
For the first few times I’d just manually scale down the old ReplicaSet to 0 (yes that means downtime) so the new one can come online, but this became tedious very quickly as it kept happening fairly often. I tried searching for the GitOps best practices for managing persistence, without much (any) luck. Even the multi-attach error is barely mentioned anywhere.
At first I thought about changing how PersistentVolumeClaims are used. Maybe using accessModes ReadWriteMany would solve it? It’d definitely allow for multiple Pods to bind the same PersistentVolume, but I wasn’t sure how safe that’d be and I’d rather not have data corruption.
So I rather went with the way the official docs cover for deploying Cassandra on Kubernetes: using StatefulSets. Both the Prometheus and Grafana Helm charts allow configuration of persistence. For Grafana to use StatefulSet the persistence.type value should be set to statefulset. For Prometheus it can be configured separately for AlertManager and the Prometheus server by setting alertmanager.statefulSet.enabled and server.statefulSet.enabled respectively to true.
This solved the problem of the apps getting stuck “progressing”. I’ll see if there are any issues about data consistency, but so far it looks good.