
アプリコードを変えました。後は機械がなんとかするはずのところ、そこから何十分もかかる手動のデプロイ作業が待っていた。アプリが動く台が増えるとその時間も台数の分だけ倍増する。
理想は、コードの変更がgit上で主ブランチにコミットとして現れたら、CI/CDパイプラインがコンテナイメージを生成して(マージ前にすでにテストが通っている前提)本番環境にカナリヤの方式でデプロイされる。
#とは
飛ばした飛ばした。カナリヤリリースとは、並行で新旧環境が存在して、ユーザーの一部だけ新しい環境を参照する。問題なければその割合を徐々に上げて最終的に全ユーザーが新環境を見るようになる。
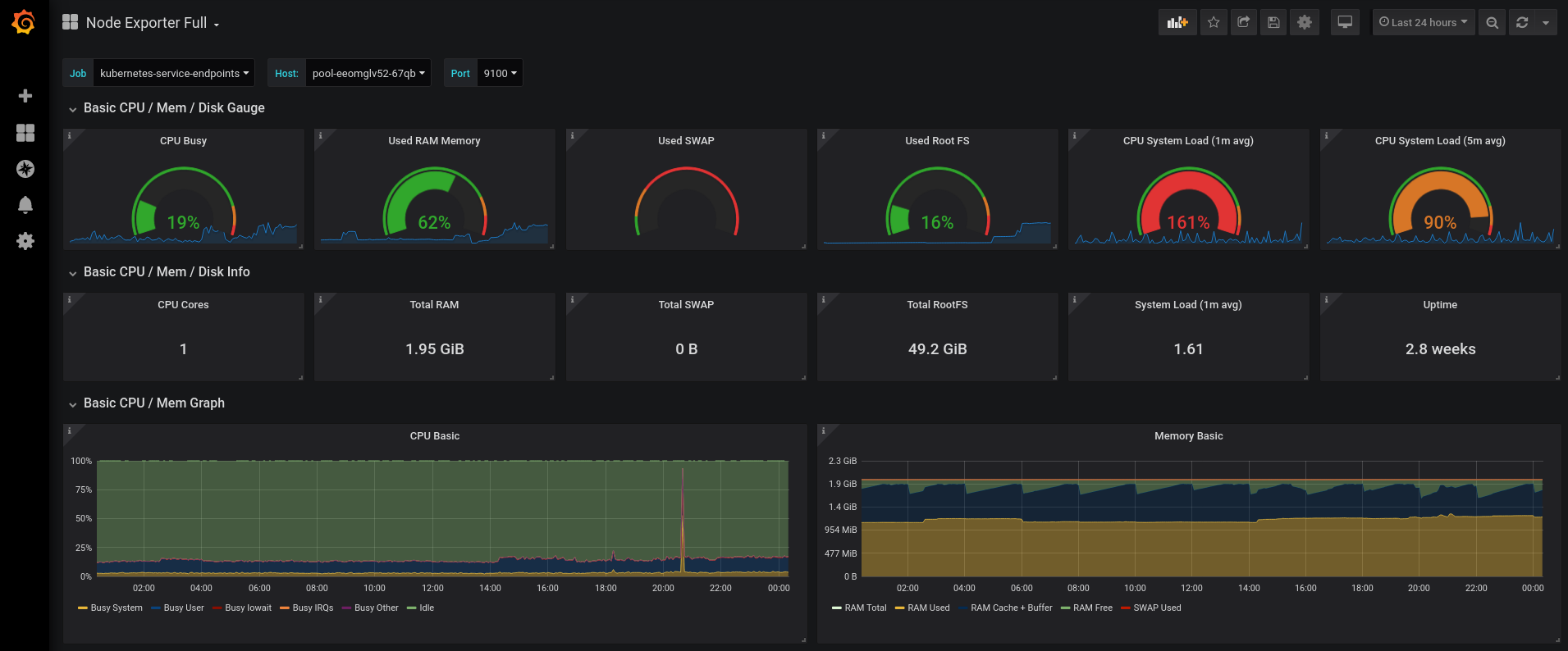
「問題なければ」の確認はアプリの種類によっていろんな指標に基づいて判断されるが、重要なのは「異常なし」。理想でいうと運用に取って重要な指標が常時取得・記録され、それを元に正常か否かが判断できる。一般的な指標でいえばエラー率やレスポンス時間、CPU使用率とかがある。
よく見る光景

青緑(ブルーグリーン)デプロイの方式で新旧環境共存のところまでは一緒だが、そこで生存確認(ヘルスチェック)さえ取れれば一気に全ユーザーを新環境につなぐ。
そこでエラー率が跳ね上がったら数分で検知され、インフラ担当が慌ててリリースを旧環境に戻す。運がよければ旧環境がまだクラウドに存在してて、切り替えるだけで済むが、もう消滅してれば再度ロールバックして再デプロイする。
例えばエラーにはならないが、かなり遅くなった「だけ」の問題だったら、気付きすらせず、サポートにお客さんから文句の問い合わせが流れてきたら対応し始める。もちろんそういう問い合わせがくるだけで信頼性が低下しビジネスに悪影響をもたらす。

カナリヤする
KubernetesのDeploymentは基本上記のような青緑デプロイで動く。新しいReplicaSetが作られPodのヘルスチェックが通ったらそれが正となって前のやつが削減される。残念ながらそのヘルスチェックが完璧なものではないし、そもそも通信流されてない状態で本当に正しいのかもわからない。
今年のスペインのKubeConで発表されたArgo Rolloutsならカナリヤができる。最近流行りのGitOpsならArgoCDがほぼ定番で、11月に発表されたAWSのGitOps Engineの2柱の一つにもなった。
既存のDeploymentから乗り換えるにはそのDeploymentをRolloutに改名して strategy を定義する。template の分とかラベルの定義は一緒でDeploymentの上位。 strategy は blueGreen と canary の2種類あって、もちろん後者が使いたい。
steps:- setWeight: 20- pause:duration: 60- setWeight: 50- pause:duration: 300
このようにCIで見慣れた steps として新環境の割合を調整したり、一定時間デプロイを一時停止することもできる。時間指定なしで停止すると、つまり手動で確認してから手動で続けることを意味する。やりたい人はどうぞやってください、俺は自動化したい。

確認は?
気づく人は気づいたと思うが、上記には何の確認もない。正常運転なのかの確認は手動でされるとの想定。それはするつもりも暇もないから自動化したい。Argo Rolloutsではそれもできる。
サイトの方のドキュメントにはまだ反映されてないようだが、GitHubを見るとAnalysis(分析)機能が目に入る。Prometheusで集計されるメトリクスで正常運転が確認できると、異常検知も容易。
そうするために AnalysisTemplate のCRDを定義して、その中で参照されるメトリクスを全部定義できる。Prometheusのサーバーが monitoring NSで動いててIngressControllerはtraefikを使っているなら、「エラー率が一割未満」を要求する確認は以下のようになる。
そして Rollout の方でそれを参照すると、チェックが通らなかったらデプロイがロールバックされ、Degradedとして扱われる。分析はデプロイ中にずっとやってほしい場合は canary 配下に置く。
strategy:
canary:
analysis:
templateName: success-rate
args:
- name: backend
value: "my-service-backend-name"
steps:
- setWeight: 20
- pause:
duration: 30
特定の段階まで進んでのチェックは steps の中に analysis を置く。
これだ
やりたかったことはこれで実現できるし、Prometheusに限らずJobとかでも指標が集められるので拡張性もピカイチ。Prometheusのクエリが自由に書ける段階でもうすでに拡張性に文句はなかったが。
Prometheusですでに「通常」が定義されアラートが飛ぶようになっている場合はクエリもすでに手元にできてるはずなので、SREを深夜に起こすだけじゃなくデプロイの時も役に立つ。
Argo Rolloutsの使い方の例は開発者がGitHubには上げているが、nginxのIngressControllerが前提になってたり、Prometheusのクエリがタイポったりするので調整の上勉強の題材にしよう。また、Kubernetesではよくあるように、まだ v1alpha1 のAPIであっていつどう変わるかも知らないので本番運用するならご承知の上で。個人プロジェクトはで早速使っているしWindowsみたいに勝手に更新されることもないので心配はないが、万が一バグにあたった時に更新は慎重に。