

Last year I had a brief affair with Longhorn. It’s a tool that abstracts the interface to interact with volumes (in my case in Kubernetes) from where the underlying data actually lives. In my case, my cluster consists of three small nodes, and back then most of the data lived in local-path provisioned volumes. Using local-path means that the data is physically on the host machine instead of some virtually mounted filesystem. This also means that once an application has a PVC, it can’t be assigned to any other node (it results in a “conflict”).
Adding Grafana annotations based on Argo CD events
I was thinking about how nice it would be if I could see on my main Grafana dashboard (the only one I use at this point actually) when there are new versions of something deployed. This way if by chance there is a problem with something afterwards I can see at a glance what could have gone wrong. Also I really like just looking at that Grafana dashboard and see that everything is alive and well. (Except when it isn’t.)
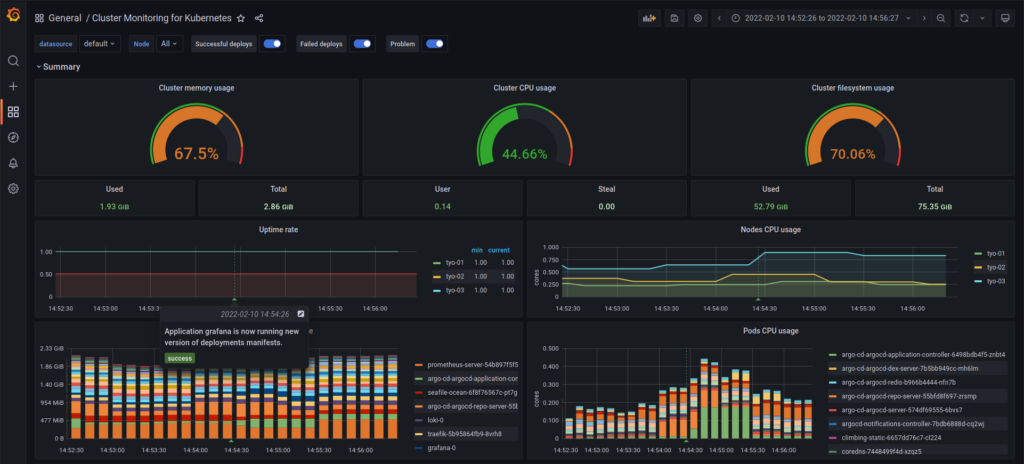
When I accidentally Longhorn CSI
Symptoms: CPU load on all the nodes, but not the pods. Looking at Grafana, I noticed that CPU load on some of my nodes was constantly very high. At the same time, even the total CPU use of all the pods summed wasn’t above 0.4. What gives? This usually gives that the control plane is getting fried by something. It may be trying to relieve disk pressure, or in this case, trying to revive CSI.
Trying to figure out what was causing problems I checked the pods in kube-system with kubectl get pods -n kube-system. It quickly became apparent that there is a problem: disk-related pods like csi-resizer, csi-snapsotter and csi-provisioner were in CrashLoopBackOff.
I’ll be quite honest in that I’m not sure what the problem was. A few searches later I came to the conclusion that an earlier node reboot had left the pods with a corrupted DNS cache or something along those lines. Basically every issue I found with the symptoms I was seeing came down to DNS problems (longhorn/longhorn#2225, longhorn/longhorn#3109, rancher/k3os#811).
Alas I haven’t touched any of the networking machinery of Kubernetes (nor configured any of it for k3s) so my first idea was just the good old one from IT Crowd: “have you tried turning it off and on again?” So I did. Luckily another restart of the afflicted nodes solved the issue. I’m glad it did because I dread what I’d have had to do otherwise.
Steps to a more stable k3s cluster
It’s all too easy to kill a k3s cluster. I’ve been using k3s for years now and I’ve had plenty of adventures tweaking various aspects of running it. Before it’d take just a small change to an Argo Application to trigger a cascading failure. Hopefully now it’s a bit more resilient. Just a bit.

charts/stable and git references

Helm was meant to be the package manager for Kubernetes. One common problem for package managers is “how do I find my packages?” Many package systems opt for having a default central repository for stuff. Distros have their central repos for apt. Programming languages too: for Node it’s npm, for Ruby it’s RubyGems, for Java it’s Maven central, for Clojure it’s Clojars. Of course most if not all systems have a way to add other package repositories or at least some other means to pull in dependencies (referencing git commits for example).
For Helm the central repository of charts/stable used to be the obvious default. You can of course add other repositories too, but defaults are powerful and many people will just give up if something is not available in the default source. On the other hand, having everything in one place puts a huge burden on the maintainers of that one place, as was the case of charts/stable. So they deprecated it.
Upgrading my cluster

My cluster is now running on k3s 1.20.6 and Argo CD 2.0.0 with its Helm chart at 3.2.2. Actually, upgrading Argo itself wasn’t much of a problem. I just changed the targetRevision of the Application and it was up and running in a few minutes. Then a few days later things got interesting.
There were no downtimes, but I noticed that Argo started failing to sync itself. Apparently a new minor version of the Helm chart came out (though it was still the same application version) that added support for the networking.k8s.io/v1 version of Ingress. However, it also accidentally broke clusters running Kubernetes before 1.19. And mine was one such.
While the Argo people are figuring out how to fix this (if), I decided to go and take this opportunity to upgrade my cluster. This wasn’t as painless as it should’ve been though.
Dealing with DiskPressure
My 4-node k3s cluster (where this blog is hosted too) kept dying every now and then. Looking at kubectl describe nodes it quickly became evident that this was caused by the nodes running out of disk space. Once a node gets tainted with HasDiskPressure, pods might get evicted and the kubelet will be using (quite a lot of) CPU trying to free disk space by garbage collecting container images and freeing ephemeral storage.
My setup by default uses local storage (the local-path provider) where volumes are actually local folders on the node. This means that pods that use persistence are stuck with the same node forever and can’t just move around. This makes eviction a problem, since they have nowhere else to go. It also means that disk usage is actually disk usage on the node, and not on some block volume over the network.
GitOps with Argo
It’s been a year since I wrote about bootstrapping a cluster with Argo and using Argo Rollouts for canary deploys based on Prometheus metrics. Since then many things have changed. I moved from Digital Ocean to Linode (mostly because Linode has a Tokyo region) and from a single-node k3s “cluster” to a 4-node one. But most of how I use Argo CD for GitOps hasn’t changed.

How does Kubernetes select labels?
kubectl has the feature to select objects by filtering on labels using the -l flag. Labels are key-value pairs attached to objects as metadata and they don’t have to be unique. I’ve most often seen them used to identify what project or app an individual resource belongs to. Helm uses labels to mark resources with the app, chart and revision they belong to.
But wait, if they’re not unique and there is a way to select multiple values with set operators, how does that work? The database backing Kubernetes by default, etcd is a key-value store. While it can natively select multiple records by prefix matching, it’d be hard to imagine labels working like that. There are many of them and the selectors are complex.
So I dove into Kubernetes’s source code to figure out how it works.
GitOps and Kubernetes persistence
A while back I wrote about bootstrapping a Kubernetes cluster. I’ve been refining the setup so that it requires as little manual kubectl‘ing as possible. I still use ArgoCD to get everything rolling, and there is one bit that kept going red: persistent volumes.
