
Last year I gave Longhorn a try. It was a nice proposition for me: I was using local storage anyway, so the idea that pods would be independent of the nodes sounded delicious. Except the price was way too much.
At the time I thought that the only problem was Prometheus, which in itself is pretty heavy on disk IO, but it turns out the issue was with Longhorn itself. Also, as I found out, I wasn’t thorough enough deleting Longhorn stuff, which resulted in quite a few headaches this year.

Both my master node and the node that had Prometheus were seeing really high loads nonstop, even though my miniature cluster has basically no traffic whatsoever. Eventually I went so far as to disable Prometheus as well, but that didn’t solve the issues either.
In the end I got fed up with the instability and decided to get it sorted out for good. I wanted to upgrade both my host OS and the running Kubernetes (k3s) version, so it was as good an occasion as any. All year I was struggling with the system journal (controlled through journalctl) of the master node and the node that used to host Prometheus filling up the disk. Now I took the time to actually scroll into the journal, and a bunch of recurring error logs caught my attention. They were all mentioning Longhorn? A year after I supposedly uninstalled it?
Turns out there were a metric ton of trash left behind by Longhorn (or maybe Helm?), still running and hogging up resources, filling my system journal with error messages (which in turn filled up the disk completely causing a whole bunch of other problems). I found them by brute-force grepping all the resources in the cluster:
kubectl api-resources --verbs=list --namespaced -o name | xargs -n 1 kubectl get --show-kind --ignore-not-found -n kube-system | grep longhornThere were a lot. Mostly CRDs, which apparently Helm wasn’t nice enough to get rid of. All these stuff under longhorn.io: engines, engineimages, nodes, replicas, volume (aliased as v too), recurringjobs, backuptargets, a bunch of Kubernetes coordination leases (lease.coordination.k8s.io) and a ton of service accounts, config maps and secrets.
Since I was definitely not using Longhorn anymore, I went around deleting them all. Manually. As it often is the case with persistence related stuff, I had to patch the finalizers out of many of them for the deleted to actually work, for example: kubectl -n kube-system patch engines.longhorn.io pvc-a9d93053-63bd-484f-b559-0d6db40472d9-e-a1e298d9 -p '{"metadata":{"finalizers":[]}}' --type=merge. Mind I could safely do this because I had no data in anything controlled by Longhorn anymore, I wasn’t using it anymore, and so I was risking nothing. Be sure you know what you’re doing before pressing enter on a destructive command.
The results were immediate. These are the November graphs for my master node. Can you spot where I nuked all the Longhorn trash? It should be pretty obvious. The graphs of the node that used to have Prometheus (and now does again, without any issues) looked just the same.
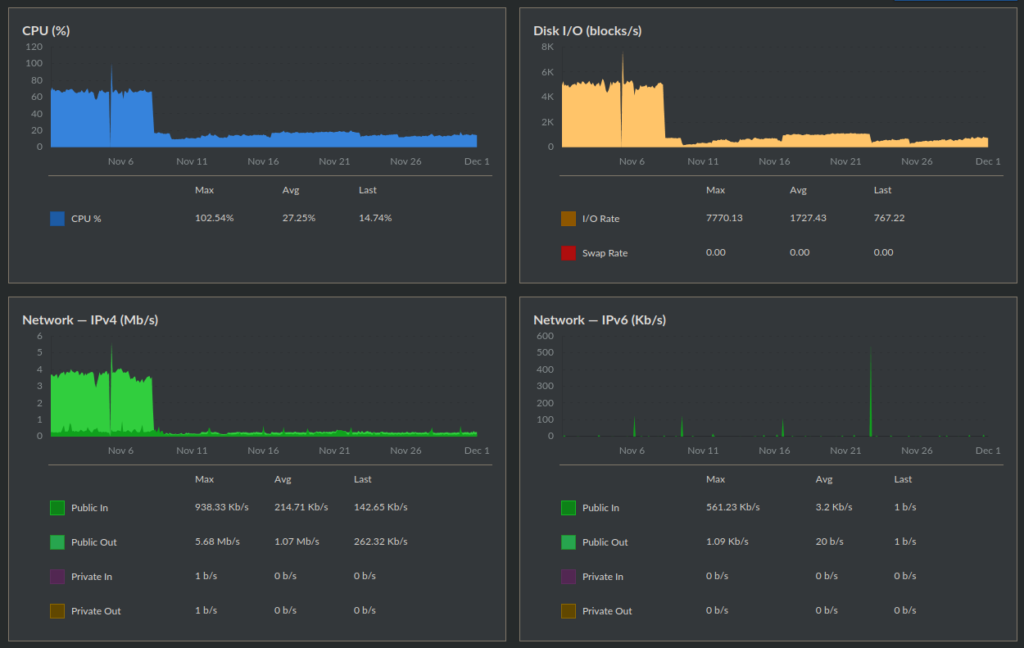
So yeah, if you install something using a Helm chart, and that thing generates a ton of Custom Resource Definitions (CRDs), then be sure that when you uninstall it, all the CRDs are gone too, because Helm seems to be a bit too lenient about leaving trash behind.